Intro
구글번역기의 도움으로 작성된 글입니다.
원문은 다음 문서를 참고하시면 됩니다.https://www.xilinx.com/content/dam/xilinx/support/documentation/ip_documentation/hbm/v1_0/pg276-axi-hbm.pdf
중요한 부분만 요약해보면,
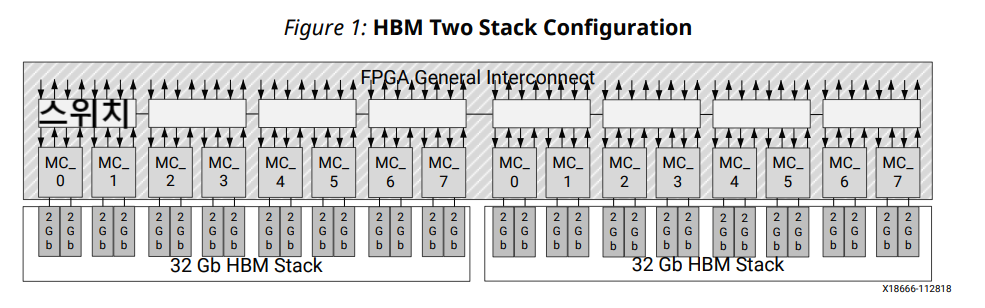
1. Xilinx HBM 솔루션은 스택당 4GB 또는 8GB 옵션으로 제공되며 거의 모든 구성이 FPGA당 2개의 스택을 포함합니다.
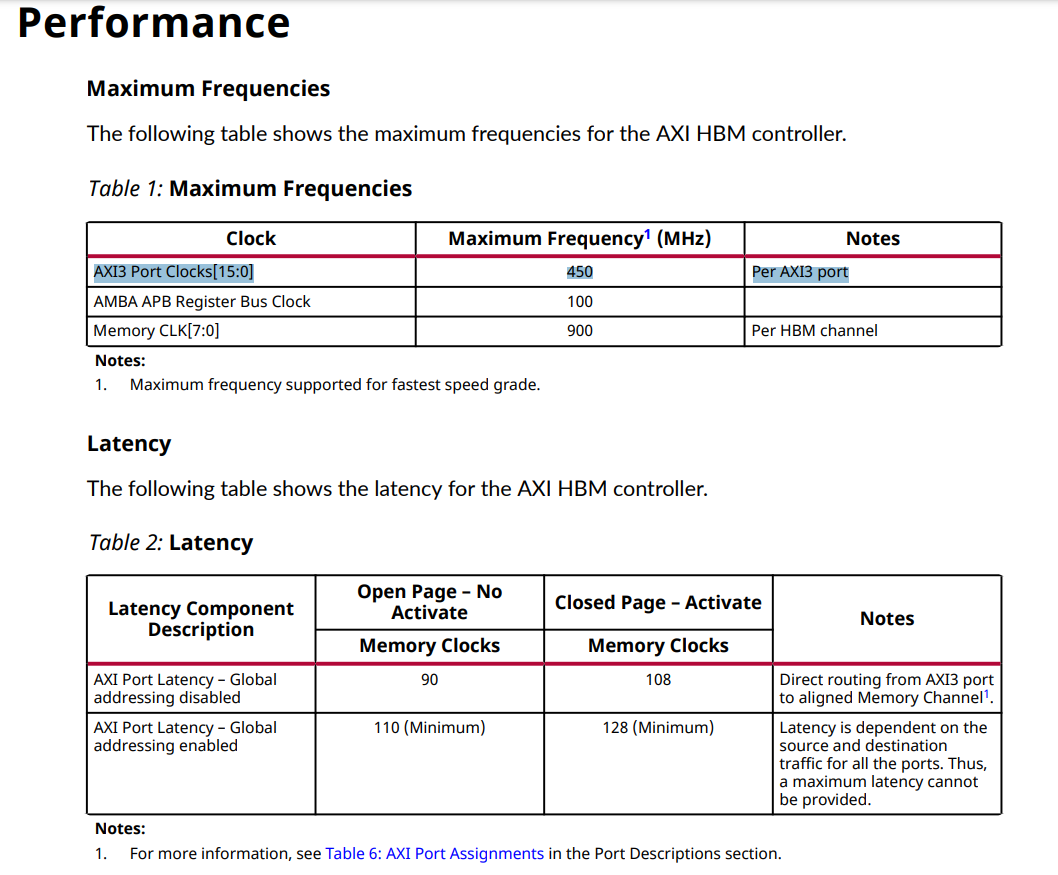
2. Performance 에서 가장 중요한 요소는 사용자 애플리케이션 로직이 AXI 포트를 통해 HBM에 액세스하는 방법이다.
3. HBM IP 의 옵션을 통해서, 상황에 맞는 (Random Access 의 short burst 가 많은 상황인지 아니면, Increase Access 의 long burst 가 많은 상황인지) Case 를 커버할 수 있다.
Overview
AXI 고대역폭 메모리 컨트롤러는 선택한 디바이스에 따라 1024b datawidth HBM 스택 중 하나 또는 둘 모두에 대한 액세스를 제공합니다. 4H 장치의 경우 64Gb (8GB) (Alveo 의 HBM 이 사용중) 또는 8H 장치의 경우 128Gb (16GB). 각 스택은 8개의 독립적인 메모리 채널로 분할되며, 각 채널은 2개의 64비트 의사(Pseudo) 채널로 다시 나뉩니다. 의사 채널 메모리 액세스는 메모리의 자체 섹션(스택 용량의 1/16)으로 제한됩니다. 또한, 각 메모리 채널은 전역 기준 클록의 정수 분할인 독립적인 클록 속도로 작동할 수 있습니다.
AXI HBM 컨트롤러는 여러 방식으로 HBM과 CLB 기반 사용자 로직 간의 인터페이스를 단순화했습니다. AXI3 프로토콜은 검증된 표준화된 인터페이스를 제공하기 위해 선택되었습니다. 제공된 16개의 AXI 포트는 HBM의 총 처리량과 일치합니다. 각 포트는 사용자 로직에 필요한 클럭 속도를 낮추기 위해 4:1 비율로 작동합니다. 이 비율에는 256비트(4 × 64 (HBM 자체의 Data width))의 포트 너비가 필요합니다. 각 AXI3 채널에는 필요한 대역폭을 얻기 위해 트랜잭션을 재정렬하는 데 도움이 되는 6비트 AXI ID 포트가 있습니다. 선택한 AXI3 채널에서 트랜잭션이 다른 ID 태그를 사용하여 트리거되면 트랜잭션은 AXI3 프로토콜에 따라 재정렬됩니다. 반대로 선택한 AXI3 채널 트랜잭션이 동일한 ID 태그를 사용하여 트리거되면 트랜잭션은 트리거된 순서대로 순차적으로 실행됩니다. 포트는 혼잡을 줄이기 위해 일반 상호 연결을 통해 분산되며 각 포트는 독립적인 클록 도메인을 기반으로 합니다. 고유한 등록된 열 인터페이스에 연결된 각 AXI 포트와 함께 이러한 유연성은 혼잡을 줄이고 타이밍 폐쇄를 용이하게 합니다. 16 × 16 AXI 크로스바 스위치가 이 코어에 포함되어 있어 각 메모리 포트가 16개의 모든 의사 채널을 지정하여 전체 HBM 공간에 액세스할 수 있습니다. 2-스택 시스템의 경우 다음 4H 장치 그림과 같이 두 HBM 스택에 직접 액세스할 수 있도록 32 × 32 크로스바로 확장됩니다.
Lateral AXI Switch Access Throughput Loss
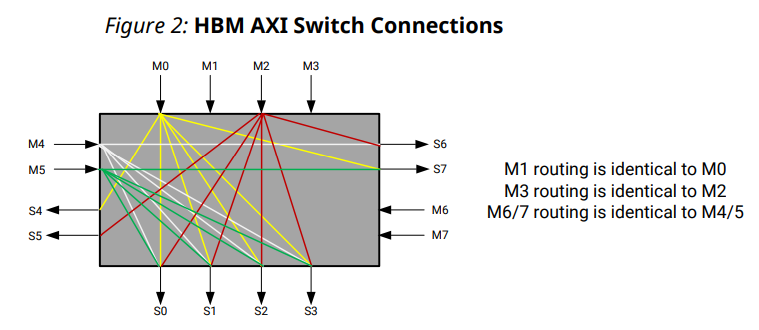
스위치 내 4개의 마스터 x 4개의 슬레이브 세트 사이에 두 개의 측면 연결이 제공되며, 하나는 M0 및 M1에 연결되고 다른 하나는 M2 및 M3에 연결됩니다. 공유 연결은 측면에서 최대 처리량을 전체 대역폭의 50%로 제한하지만 모든 AXI 포트에서 HBM의 모든 부분으로 전역 주소 지정을 가능하게 합니다. 쓰기 사이클의 경우 측면 채널에서 마스터 간에 전환할 때 단일 데드 사이클이 있습니다. 이 삽입된 주기로 인한 처리량 손실은 쓰기의 블록 크기와 처리량이 HBM MC 제한이 아닌 스위치 제한 범위에 따라 다릅니다.
AXI Switch 인스턴스 내의 East/West 트랜잭션의 경우 측면 성능 손실이 없습니다. AXI Switch 인스턴스를 떠나는 East/West 트랜잭션의 경우 측면 처리량 성능 손실이 발생합니다. 스위치를 교차하는 동안 AXI 마스터에 의해 중단된 트랜잭션은 계속해서 측면 경로를 예약하여 다른 채널에서 사용하는 것을 방지합니다. 예를 들어, 교차 스위치가 필요한 메모리 위치에서 읽는 AXI 포트는 전체 데이터 버스트를 수신할 수 없으며 트랜잭션 중간에 RREADY를 선언 해제합니다. 이로 인해 측면 경로가 이 트랜잭션에 의해 요구된 상태로 유지되고 동일한 경로가 필요한 다른 AXI 채널의 트랜잭션을 처리할 수 없습니다.
쓰기 트랜잭션에서 유사한 동작이 발생할 수 있습니다. 쓰기 명령이 실행되고 스위치가 수락하면 해당 데이터 경로가 예약되고 데이터가 완전히 전송될 때까지 계속 유지됩니다. AXI 프로토콜을 사용하면 명령을 먼저 보내고 나중에 데이터를 보낼 수 있습니다. 그러나 데이터 경로가 다른 명령에 필요한 측면 연결인 경우 그렇게 하면 전체 스위치 성능에 상당한 영향을 미칠 수 있습니다. 쓰기 명령은 해당 쓰기 데이터를 사용할 수 있을 때만 보내는 것이 좋습니다.

MC (Memory Contorller) 처리량이 거의 100%인 쓰기 시퀀스는 추가 스위칭 주기로 인해 처리량이 가장 크게 떨어집니다. 결과적으로 작은 블록은 큰 블록보다 손실률이 더 큽니다. 다음 그림은 32바이트 및 256바이트 트랜잭션의 측면 처리량 손실을 보여줍니다. 32바이트 트랜잭션의 경우 두 개의 마스터가 각각 AXI 스위치를 가로질러야 하는 3개의 32바이트 버스트를 발행합니다. 256바이트 트랜잭션의 경우 각 마스터는 AXI 스위치를 측면으로 통과해야 하는 2개의 256바이트 버스트를 발행합니다. 32바이트의 경우 각 마스터에 대한 각 데이터 버스트 사이에 하나의 클럭이 삽입되어 총 12개의 클럭 사이클이 6비트의 데이터를 이동합니다. 256바이트의 경우 각 256바이트 버스트 사이에 하나의 유휴 클록이 삽입되어 총 36개의 클록 사이클이 32비트의 데이터를 이동하게 됩니다. M2 및 M3은 하나의 측면 슬레이브 포트에만 액세스할 수 있기 때문에 이러한 포트의 총 대역폭은 두 마스터 간에 분할됩니다. 이는 마스터와 단일 슬레이브 포트를 공유하는 두 마스터 간의 전환을 위한 추가 클록 주기로 인해 약 25%의 32바이트 트랜잭션에 대한 전체 효율성을 초래합니다. 256바이트 트랜잭션의 경우 이러한 동일한 동작으로 인해 약 44.4%의 효율성이 발생합니다.

Resource Use
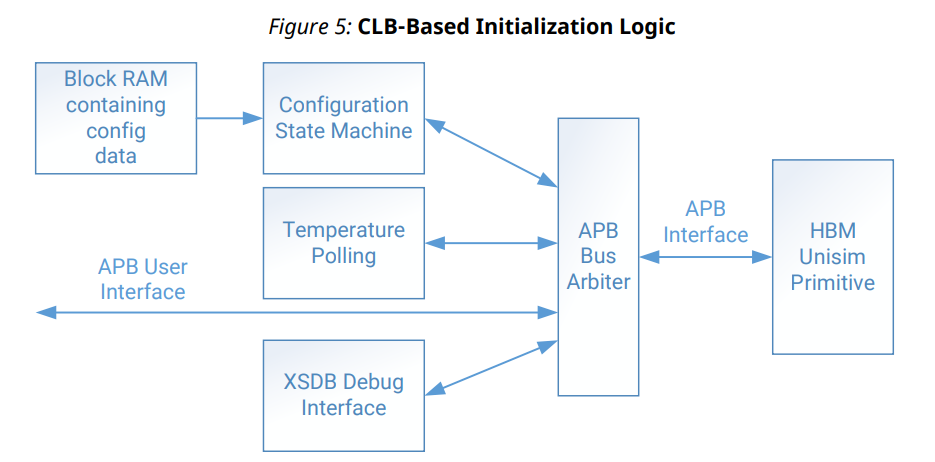
HBM 스택 컨트롤러를 지원하려면 최소 CLB 및 블록 RAM 리소스가 필요합니다. 주로 로직은 Vivado® HBM 마법사에 설정된 값을 기반으로 레지스터 초기화에 사용됩니다. 추가 CLB 리소스는 설계에 필요한 클록, 활성화된 AXI 인터페이스 및 APB 레지스터 인터페이스에 사용됩니다. 다음 그림은 HBM 컨트롤러 초기화 로직을 보여줍니다.
Port Descriptions
Port 설명 부분은 생략
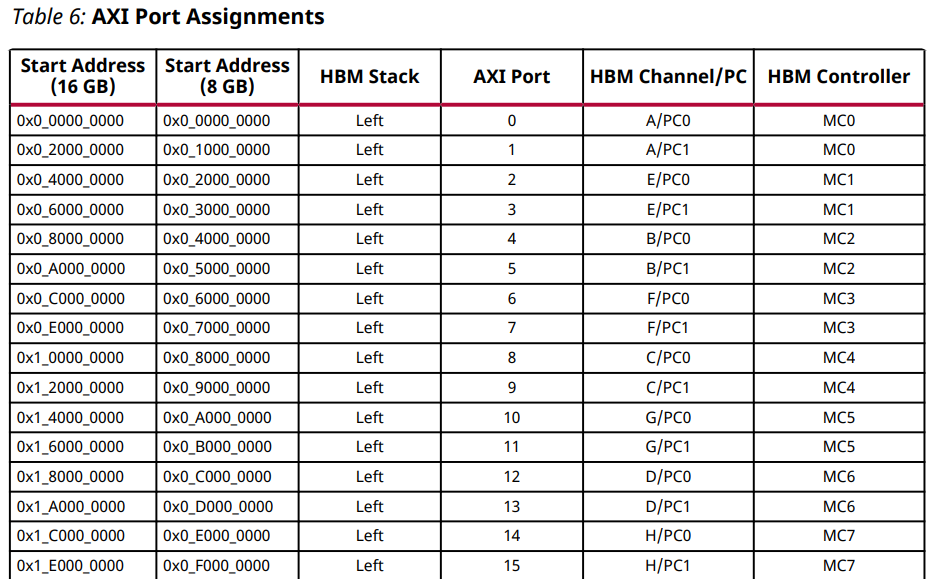
다음 표는 일반 상호 연결의 AXI 포트 할당을 보여줍니다. 여기에는 각 HBM 채널과 연관된 시작 주소, 메모리 컨트롤러 및 정렬된 의사 채널이 포함됩니다. 비전역 주소 모드에서 AXI 포트는 연결된 의사 채널에만 액세스할 수 있습니다. 각 AXI 포트에는 2Gb(4H 스택) 또는 4Gb(8H 스택)의 고정 주소 맵이 있습니다. 따라서 비전역 주소 모드에서 각 AXI 포트는 첫 번째 열에 언급된 시작 주소와 다음 의사 채널의 시작 주소 이전에 끝나는 주소 공간에 매핑되어야 합니다. 전역 주소 모드에서 각 포트는 모든 의사 채널에 액세스할 수 있지만 성능과 대기 시간은 다릅니다.
(이 부분을 고려해서, Mermory Address Mapping 을 해야함!)


HBM Performance Concepts
HBM 솔루션의 전체 성능은 여러 요인에 따라 달라집니다.
• HBM 스택 작동 주파수
• 사용자 애플리케이션의 AXI 포트 주파수
• HBM 주소 맵 선택
• 전역 주소 지정 모드
• HBM IP 내에서 선택된 재정렬 옵션
• HBM 스택 온도
가장 중요한 요소는 사용자 애플리케이션 로직이 AXI 포트를 통해 HBM에 액세스하는 방법입니다. 시스템 설계자는 설계에서 HBM 메모리 솔루션의 성능을 평가할 때 이러한 모든 요소가 상호 작용하는 방식을 고려해야 합니다.
HBM Topology
Xilinx HBM 솔루션은 스택당 4GB 또는 8GB 옵션으로 제공되며 거의 모든 구성이 FPGA당 2개의 스택을 포함합니다. 이는 이러한 이중 스택 장치에 대해 총 8GB 또는 16GB의 사용 가능한 메모리가 있음을 의미합니다. HBM 스택의 총 데이터 비트 너비는 각각 128비트의 8개 채널로 나누어진 1024비트입니다. 각 채널은 의사 채널 모드에서 HBM에 액세스하는 단일 메모리 컨트롤러에 의해 서비스되며, 이는 공유 명령/주소/제어(CAC) 버스가 있는 2개의 반독립적 64비트 데이터 채널을 의미합니다. 스택 장치당 4GB에는 채널당 4Gb가 있고 각 채널에는 2개의 2Gb 또는 256MB 의사 채널이 있습니다. 스택 장치당 8GB에는 채널당 8Gb가 있고 각 채널에는 4Gb 또는 512MB 의사 채널이 2개 있습니다. 대부분의 HBM 프로토콜 요구 사항 및 타이밍은 의사 채널 기반으로 평가할 수 있습니다. 즉, tRRD를 고려하지 않고 PC0 및 PC1에 두 개의 활성화 명령을 연속적으로 실행할 수 있습니다. 두 개의 Activate 명령이 동일한 의사 채널에 연속적으로 발행되면 tRRD가 먼저 만료되어야 두 번째 Activate 명령이 발행될 수 있습니다. HBM은 의사 채널 모드에서 항상 4의 버스트 길이로 작동합니다. HBM 프로토콜은 DDR4 메모리의 프로토콜과 거의 일치하므로 동일한 성능 및 프로토콜 개념이 많이 적용됩니다. HBM의 클럭 속도는 Vivado IDE의 IP 구성 옵션에서 설정됩니다. HBM은 DDR(Double Data Rate) 메모리이므로 데이터 버스는 인터페이스 클록 속도의 두 배로 토글합니다. (현재 450 MHz 로 사용중이니까, 900MHz 의 Data 토글)
Raw Throughput Evaluation
HBM 스택의 원시 처리량과 이 데이터 속도와 일치하도록 사용자 논리를 설계하는 방법을 이해하는 것이 중요합니다.
각 HBM 스택에는 8개의 채널이 있고 각 채널에는 전용 메모리 컨트롤러가 있으며 각 메모리 컨트롤러는 의사 채널 모드에서 작동하고 각 의사 채널의 너비는 64비트이며 데이터 비트는 IP 구성에 설정된 HBM 클록 속도의 두 배로 토글됩니다.
HBM IP가 900MHz 클록 속도로 구성된 경우 단일 HBM 스택에 대한 토글 속도는 다음 공식을 사용하여 평가할 수 있습니다.
(의사 채널당 64비트) x (메모리 컨트롤러당 2개의 유사 채널) x (8채널) x 900MHz x 2 스택당 초당 1,843,200Mb (이론상 225GB/s 의 BW 에 해당)

또는 스택당 초당 230,400MB 가 됩니다.
이중 스택 장치의 경우 이 값을 초당 460,800MB로 두 배로 늘립니다. (Stack 이 2개니까.)
사용자 논리 관점에서 HBM의 각 AXI 포트는 256비트 너비이며 스택의 의사 채널당 하나의 AXI 포트가 있습니다.
위의 예에서 사용자 로직은 HBM이 900MHz에서 실행 중일 때 HBM의 토글 속도와 일치하도록 450MHz에서 AXI 포트를 클럭해야 합니다. 이는 다음 공식으로 평가됩니다. (AXI 포트당 256비트) x (메모리 컨트롤러당 포트 2개) x (8채널) x 450MHz 결과적으로 스택당 초당 1,843,200Mb 또는 스택당 초당 230,400MB가 됩니다.
32개의 AXI 포트가 있는 듀얼 스택 장치의 경우 초당 460,800MB의 경우 이 값을 두 배로 늘립니다. 이것은 원시 HBM 처리량 계산이지만 기존의 모든 휘발성 메모리와 마찬가지로 HBM 스택의 어레이는 데이터 무결성을 유지하기 위해 새로 고쳐야 합니다. HBM 스택의 기본 새로 고침 간격(tREFI)은 3.9μs입니다. 4H 장치의 경우 새로 고침 명령 기간(tRFC)은 260ns이고 8H 장치의 경우 350ns입니다. 4H 장치의 원시 처리량에 새로 고침 오버헤드를 추가하면 최대 효율의 약 7%가 손실되고 8H 장치는 약 9%가 손실됩니다. 기존 휘발성 메모리의 경우와 마찬가지로 tREFI는 온도가 증가함에 따라 감소하므로 스택이 가열됨에 따라 오버헤드를 새로 고치기 위해 사용 가능한 HBM 인터페이스 시간이 더 많이 손실됩니다. 3.9μs의 기본 속도는 0°C ~ 85°C의 온도에 사용됩니다. 85°C와 95°C 사이에서 tREFI는 1.95μs로 감소합니다.
AXI Considerations
HBM IP는 32바이트(256비트)에 대해 0x5의 고정 AxSIZE가 필요하며 선형 액세스에 대해 더 높은 성능을 얻으려면 최소 AxLEN을 0x1로 설정하는 것이 좋습니다. 크기가 작은 AXI 쓰기는 WSTRB 포트를 사용하여 지원되지만 이러한 액세스는 전체 시스템 성능을 저하시킵니다. 이는 8바이트 쓰기에 사용되는 것과 동일한 양의 HBM 프로토콜 실행 및 인터페이스 시간이 전체 32바이트 쓰기를 서비스하는 데 사용되기 때문입니다. 이 예에서 유효 피크 대역폭은 이론상 최대값의 25%에 불과합니다.
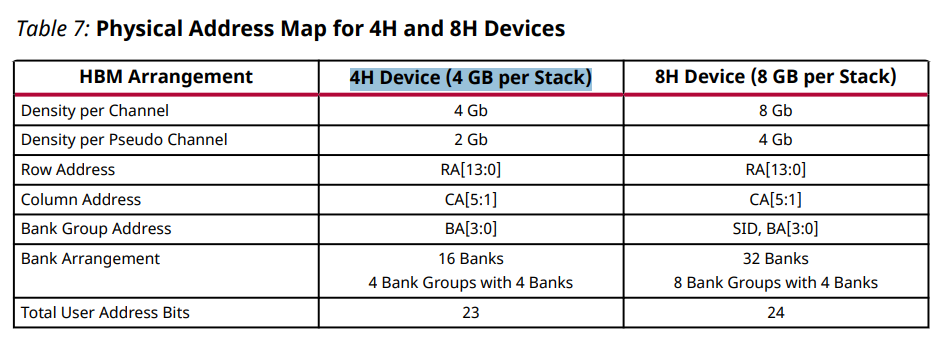
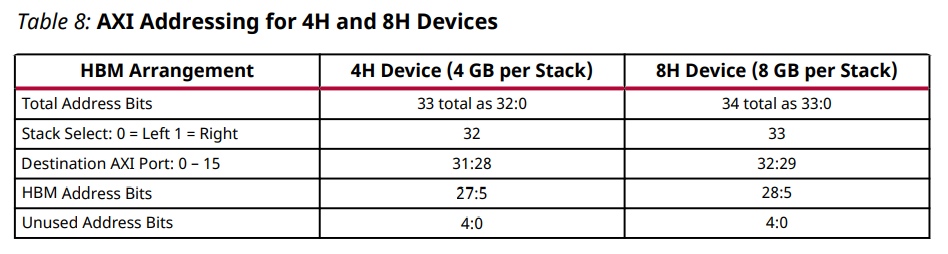
4H 장치의 전체 주소 공간은 32비트이고 8H 장치의 경우 33비트입니다. 다음 표는 이러한 장치에 대한 AXI 주소 지정을 설명합니다.
HBM 작동은 기존 휘발성 메모리의 작동을 밀접하게 따르며 특히 DDR4와 유사합니다. 프로토콜 작동의 기본은 메모리 어레이에 액세스할 때 결과적인 효율성을 결정하며, 이는 사용자 AXI 액세스 패턴 및 작동 중에 사용자 로직이 AXI 채널을 구동하는 방법과 함께 중요한 고려 사항이어야 합니다. DDR4와 마찬가지로 HBM은 메모리에 뱅크 및 뱅크 그룹의 개념을 사용하고 이러한 개념을 활용하여 매우 효율적인 어레이 액세스 패턴을 달성합니다. 4H 장치에는 총 16개의 뱅크가 있으며 각각 4개의 뱅크가 있는 4개의 뱅크 그룹으로 배열됩니다. 8H 장치에는 4개의 뱅크가 있는 8개의 뱅크 그룹으로 배열된 32개의 뱅크가 있습니다.
HBM은 뱅크당 하나의 활성 행(Row) 주소를 지원합니다. 다른 뱅크그룹에 있는 뱅크사이의 프로토콜 액세스 시간은 동일한 뱅크그룹에 있는 뱅크에 액세스할 때보다 짧으며 해당 뱅크 내의 다른 행이 활성화되기 전에 뱅크 내 현재 활성화된 행이 사전 충전되어야 합니다. Row가 Bank 내에서 활성화되면 Row를 변경하기 전에 해당 Row 내에서 여러 Column 액세스를 수행하는 것이 좋습니다. 이렇게 하면 페이지 적중률(hit rate)이 높아지는 것으로 간주되어 효율성이 높아집니다.
기본적으로 HBM IP는 Bank Group Interleave 옵션이 활성화된 Row Bank Column 주소 지정 맵으로 설정됩니다. 이러한 기본 설정에서 최상위 주소 비트는 행 주소(RAx) 비트이며, 이 중 뱅크당 한 번에 하나의 행 주소만 활성화될 수 있습니다. 중간 주소 비트는 은행 주소 비트로, 은행 그룹의 경우 BGx로 표시되고 은행 주소의 경우 BAx로 표시됩니다. 다음으로 낮은 주소 범위는 CAx로 표시되는 열 주소 비트이며 쓰기 및 읽기 명령에 의해 액세스됩니다.
Bank Group Interleave 옵션은 Bank Group 주소 지정의 최하위 비트인 BG0이 HBM 메모리 맵(addr[5])의 최하위 사용자 주소 비트로 배치됨을 의미합니다. 기본 주소 맵에서 AxLEN이 0x1이고 AxADDR이 0x0인 AXI 트랜잭션은 HBM 인터페이스에서 두 개의 개별 명령을 실행합니다. 첫 번째는 행 0, 뱅크그룹 0, 뱅크주소 0, 열 0으로 이동합니다. 두 번째는 행 0, 뱅크 그룹 1, 뱅크주소 0 및 열 0으로 이동합니다. BG0을 최하위 비트로 사용하는 뱅크 그룹 인터리브 옵션 사용 순차 메모리 액세스를 지원합니다. 컨트롤러가 두 개의 개별 뱅크그룹에 있는 두 개의 뱅크간에 액세스를 분할하기 때문에 프로토콜 실행을 기다리는 데 소요되는 시간이 줄어듭니다. AxLEN이 0x1인 AXI 트랜잭션은 이러한 동작을 보여주지만 더 높은 효율성을 위해 이러한 개념을 완전히 활용하려면 더 긴 트랜잭션 길이 또는 뱅크 그룹 전체에서 뱅크 주소에 매핑된 트래픽 스트림을 활용하는 더 많은 고려가 필요합니다. 기본 주소 맵 옵션은 AxLEN이 0x1 이상일 때 Bank Group Interleave 옵션이 일부 프로토콜 노출을 완화하기 때문에 짧은 혼합 트래픽에 이상적입니다. 이 기본 주소 맵 옵션은 AXI 재정렬 코어도 지원하므로 효율성에 도움이 되지만 대기 시간이 늘어날 수 있습니다.
행 열 은행 주소 맵 옵션은 긴 순차 액세스 패턴에 이상적입니다. 이는 긴 트랜잭션 길이(예: 0x8 이상의 AxLEN)의 경우 대부분의 프로토콜 노출이 Bank Group 전환에 의해 숨겨지기 때문입니다. 이 주소 맵은 AXI 트랜잭션이 한 번에 한 방향으로만 진행될 때 가장 잘 사용됩니다. 트래픽이 방향을 변경해야 하는 경우 해당 액세스는 동일한 행/뱅크 조합을 대상으로 하여 열 액세스에 대한 페이지 히트를 보장해야 합니다. 이는 긴 쓰기 시퀀스가 서비스될 때 버스 턴어라운드를 유발하여 HBM 인터페이스에서 유휴 기간이 발생하고 효율성이 떨어지기 때문에 사용자 로직이 읽기 요청을 발행해서는 안 된다는 것을 의미합니다. 쓰기 및 읽기 액세스가 동일한 행/뱅크 조합을 대상으로 하지 않는 경우 사용자 논리는 현재 액세스 시퀀스가 완료될 때까지 방향 전환을 시도하지 않아야 합니다. 이 시나리오에서 쓰기 스트림이 실행 중이고 읽기 스트림이 다른 행/뱅크 조합에 액세스하려고 하면 새 트래픽 스트림이 페이지 누락으로만 구성되기 때문에 컨트롤러가 여러 Precharge 및 Activate 명령을 실행합니다. 이로 인해 HBM 인터페이스에서 상당한 양의 유휴 시간이 발생하고 효율성이 저하됩니다. Bank Row Column 주소 맵 옵션은 사용자 로직이 트래픽 스트림을 별도의 Bank Group 및 Bank 주소 범위로 분할한 디자인에 이상적입니다. 이는 여러 트래픽 스트림이 자체 은행 그룹/주소 조합에서 독립적으로 작동할 수 있고 필요에 따라 나머지 주소 공간을 사용할 수 있음을 의미합니다. 단순화된 예제 시나리오에는 하나는 모든 은행 그룹에서 BA0 및 BA1에 매핑되고 다른 하나는 모든 은행 그룹에서 BA2 및 BA3에 매핑되는 두 개의 스트림이 있습니다. 첫 번째 스트림은 길고 순차적이며 두 번째 스트림은 완전히 무작위적이고 짧습니다. 첫 번째 스트림은 페이지 적중률이 높기 때문에 높은 효율성을 유지합니다. 임의 주소 지정을 사용하는 두 번째 스트림은 효율성이 낮지만 첫 번째 스트림과 동일한 Bank/Row 조합을 대상으로 하지 않으므로 첫 번째 스트림에 대해 높은 효율성이 유지됩니다. 이러한 고려 사항이 없으면 트래픽 스트림이 길고 순차적인 반면 다른 트래픽 스트림은 랜덤인 경우 랜덤 스트림은 순차 스트림을 방해하여 둘 다 효율성이 낮습니다.
HBM Reordering Options
HBM IP에는 Vivado IDE의 재정렬, 새로 고침 및 절전 옵션 페이지에서 사용할 수 있는 많은 재정렬 및 새로 고침 옵션이 있습니다. 기본 행 은행 열 주소 맵 옵션을 사용하는 경우 다른 재정렬 옵션에서 선택할 수 있습니다. 그러나 사용자 지정 주소 맵 옵션을 선택하면 동적 페이지 열기 비활성화 옵션을 제외하고 많은 재정렬 옵션이 비활성화되지만 새로 고침 및 절전 옵션은 그대로 유지됩니다. 이는 재정렬 코어 로직 및 HBM 컨트롤러 내의 종속성 때문입니다. 기본 주소 맵으로 재정렬 옵션을 최대한 활용하려면 이들 각각에 대한 기능 및 성능 영향을 이해해야 합니다.
HBM 솔루션에는 두 가지 수준의 명령 재정렬이 있습니다. HBM 메모리 컨트롤러 자체에는 HBM 메모리 어레이 및 보류 중인 명령의 현재 상태를 최적화하기 위해 미리보기 로직을 사용하는 12개 항목의 딥 명령 큐가 있습니다. 이것은 기본적으로 활성화되어 있으며 DDR 컨트롤러 내에서 다른 모든 미리보기 로직과 같은 기능을 합니다. 재정렬의 다른 수준은 기본 행 은행 열 주소 맵과 함께 사용할 수 있는 64개 항목의 깊은 AXI 명령 대기열입니다. 이것은 Vivado IDE의 HBM 구성 옵션에서 Enable Request Reordering 옵션을 선택하여 사용할 수 있습니다. 재정렬에서 일관성 사용, 대기열 사용 기간 제한 재정렬 및 페이지 닫기 재정렬 사용 옵션과 상호 작용합니다. 활성화된 경우 AXI 명령 대기열은 DDR 컨트롤러의 표준 재정렬 로직과 유사하게 작동합니다. 논리는 페이지 적중률을 높이기 위해 이미 열려 있는 Bank/Row 조합을 대상으로 합니다. 다른 은행 그룹에 대한 액세스는 동일한 은행 그룹에 대한 액세스보다 승격됩니다. 컨트롤러가 즉시 활성화를 실행할 수 있는 경우 활성화되기 전에 사전 충전이 필요한 액세스를 통해 승격됩니다. 읽기/쓰기 액세스는 버스 턴어라운드를 줄이기 위해 가능한 경우 병합됩니다. 데이터 일관성이 사용자 트래픽 마스터에 의해 보장되지 않는 경우 재정렬 시 일관성coherency 활성화 옵션을 사용하면 Bank/Row 지역성을 가진 액세스가 수신된 순서대로 실행됩니다. Request Reordering이 활성화되어 있을 때 시스템에 대기 시간 제한이 있는 경우 Reorder Queue Age Limit 옵션을 기본값인 128에서 줄일 수 있습니다. 이 값은 보류 중인 명령이 맨 위로 범프되기 전에 최대 128개의 새 명령을 처리할 수 있음을 의미합니다. 대기열. 닫힌 페이지 재정렬 활성화 옵션은 대기열에 있는 모든 명령을 자동 사전 충전 작업으로 전환합니다. 이는 각 명령이 자동 사전 충전으로 표시되기 때문에 모든 쓰기 또는 읽기 액세스로 인해 새로운 뱅크가 활성화된다는 의미입니다. 이 옵션은 액세스 패턴에 무작위 주소 지정이 포함된 짧은 버스트가 있는 경우에 유용합니다. 시뮬레이션을 통해 또는 하드웨어에서 시스템 성능을 평가할 때 AXI 재정렬 대기열이 활성화될 때의 의미에 주목하는 것이 중요합니다. 첫째, 트래픽 패턴 시퀀스는 컨트롤러가 정상 상태 작동에 들어갈 만큼 충분히 길어야 합니다. 쓰기 시퀀스가 너무 짧은 경우 컨트롤러가 백프레셔 없이 들어오는 명령을 사용하기 때문에 지나치게 낙관적인 성능을 볼 수 있습니다. 읽기 시퀀스의 경우 반대입니다. 너무 적은 수의 명령이 실행되면 대부분의 시간이 데이터 전송보다 프로토콜 오버헤드에 소비되기 때문에 읽기 성능이 낮은 것으로 나타납니다. 재정렬 대기열이 활성화된 상태에서 대기 시간을 평가할 때 사용자 애플리케이션과 일치하고 특히 혼합 트래픽에서 충분히 긴 액세스 패턴을 모델링하여 재정렬 대기열 사용 기간 제한을 조정해야 하는지 확인하는 것이 중요합니다. 이 분석의 좋은 시작점은 10개의 새로 고침 주기 또는 약 40μs를 포함하는 실행 시간입니다.
HBM 메모리 컨트롤러 내에서 컨트롤러의 열기 또는 닫기 페이지 정책뿐만 아니라 미리보기 동작을 변경할 수 있습니다. 기본적으로 Look Ahead Precharge 및 Activate 옵션이 활성화되어 있으며 이는 표준 DDR 컨트롤러에서 볼 수 있는 것과 동일한 개념을 따릅니다. 이러한 옵션이 활성화되면 컨트롤러는 메모리 어레이의 현재 상태와 대기열에 있는 보류 중인 12개 명령을 고려하고 기회에 따라 사전 충전 또는 활성화 명령을 삽입합니다. Disable Dynamic Open Page(동적 열기 페이지 비활성화) 옵션은 행 변경이 필요한 대상 뱅크에 대한 개별 명령이 있을 때까지 컨트롤러가 현재 활성 행/뱅크를 열어 두도록 합니다. 이것은 사전 충전 및 활성화 순서입니다. 이것은 메모리 어레이에서 높은 수준의 지역성을 가진 낮은 대역폭 트래픽 스트림에 유용할 수 있습니다.
System-Level Considerations
전역 주소 지정 옵션을 사용하면 AXI 스위치가 대상 주소로 라우팅하는 모든 수신 포트에서 AXI 명령을 라우팅하여 HBM 어레이에 액세스할 수 있습니다. 이 라우팅은 AXI 주소의 최상위 비트인 스택 선택 비트에 의해 결정됩니다. 대상 AXI 포트는 다음 4개의 주소 비트에 의해 결정됩니다. 포트 설명의 AXI 포트 할당 테이블은 스택 및 AXI 포트 매핑을 시각적으로 보여줍니다. 측면 AXI 스위치 액세스 처리량 손실 섹션에 설명된 대로 AXI 명령이 스위치를 통과할 때 지연 및 성능 영향이 있습니다. 사용자 논리 구현 및 액세스 패턴과 함께 이러한 제한을 고려하여 사용 사례가 지원할 수 있는 순회 및 전역 주소 지정이 실행 가능한 옵션인지 결정하는 것이 중요합니다. 과도한 탐색으로 인해 너무 많은 성능 문제가 발생하는 경우 AXI 포트로 이동하는 트래픽 마스터를 대상 메모리 컨트롤러에 더 가깝게 재배열해야 할 수 있습니다. 사용자 애플리케이션에 짧은 대기 시간이 필요한 경우 전역 주소 지정 옵션은 64개 항목의 깊은 AXI 재정렬 대기열과 함께 비활성화되어야 합니다. 전역 주소 지정이 비활성화되면 AXI 명령은 더 이상 수신 포트에서 대상으로 라우팅되지 않습니다. 이 시나리오에서 AXI 명령은 수신 포트로 들어가 이 AXI 포트에 연결된 의사 채널로 직접 라우팅합니다. 이것은 AXI 스위치 로직을 우회하고 메모리 컨트롤러에 대한 최저 대기 시간 경로를 활성화합니다. AXI 재정렬을 비활성화하면 명령이 컨트롤러에서 직접 소비되고 로컬 12항목 딥 큐에서 재정렬되기 때문에 대기 시간도 감소합니다. AXI 재정렬이 활성화된 경우 명령이 서비스되기 전에 얼마 동안 대기열에 남아 있을 수 있습니다. 또한 사용자 애플리케이션이 짧은 대기 시간을 요구하는 경우 트래픽 마스터와 HBM 메모리 맵에 의해 AXI 액세스 패턴에 대해 상당한 분석을 수행해야 합니다. HBM은 DDR4의 동일한 기본 프로토콜 원칙을 따르므로 잘 정의된 액세스 패턴을 사용하여 HBM 컨트롤러 옵션과 메모리 맵을 검토하여 주어진 사용 사례에 대해 최고의 효율성을 보장해야 합니다. 최적의 결과는 해당 사용 사례에 따라 다르기 때문에 각 애플리케이션과 워크로드에는 솔루션이 다릅니다.
애플리케이션에 따라 트래픽 마스터는 단일 AXI ID 또는 여러 AXI ID만 발행할 수 있습니다. 마스터가 단일 AXI ID만 생성하는 경우 동일한 ID의 트랜잭션은 채널 수준에서 차단되고 수신된 순서대로 실행됩니다. 여러 AXI ID가 생성된 경우 활성화된 경우 AXI 재정렬 코어 내에서 재정렬됩니다. 사용자 로직이 이러한 시나리오에서 일관성을 보장하기 위해 AXI ID 또는 액세스를 관리하지 않는 경우 재정렬 시 일관성 활성화 옵션을 활성화하십시오. 전역 주소 지정이 활성화된 경우 추가 주의를 기울여야 합니다. AXI 액세스가 스위치를 탐색하는 데 걸리는 시간은 실시간으로 발생하는 다른 모든 액세스 및 라우팅과 경합하기 때문에 결정적이지 않습니다. 재정렬 시 일관성 활성화 옵션 외에도 사용자 로직은 수락된 첫 번째 액세스에 의존하는 후속 액세스를 발행하기 전에 AXI 쓰기 응답 신호(BRESP)를 대기하여 이를 관리해야 합니다. 메모리 컨트롤러의 12개 항목 명령 대기열 내에서 일관성이 항상 보장됩니다. 기존 DDR 컨트롤러의 경우와 마찬가지로 효율성을 위해 쓰기/읽기 순서 종속성을 깨뜨리지 않기 때문입니다. 트랜잭션 크기가 작거나 매우 임의적인 주소 지정이 있는 사용자 애플리케이션의 경우 또는 트래픽 마스터가 단일 AXI ID만 생성할 수 있는 경우 Xilinx® Random Access Memory Attachment IP 사용을 고려하십시오. RAMA IP는 비이상적인 트래픽 마스터 및 사용 사례가 있는 HBM 기반 설계를 지원하도록 특별히 설계되었습니다. 마스터가 단일 AXI ID만 생성하는 경우 ID 차단을 방지하기 위해 대체 AXI ID를 생성할 뿐만 아니라 효율성과 대역폭을 개선하기 위해 트랜잭션의 크기를 조정하고 재정렬할 수 있습니다. RAMA IP에 대한 자세한 내용은 RAMA LogiCORE IP 제품 가이드(PG310)에서 확인할 수 있습니다.
